Things I've learned from running Terraform in a Pod
For the last year I'm been working on the network infrastructure part of our cloud offering at Adobe. The objective was to connect some of our Pods from our clusters to the customer premises, providing connectivity to some of the systems they run in-house, like databases, Splunk or Solr.
The main components in our architecture are depicted in the diagram bellow:
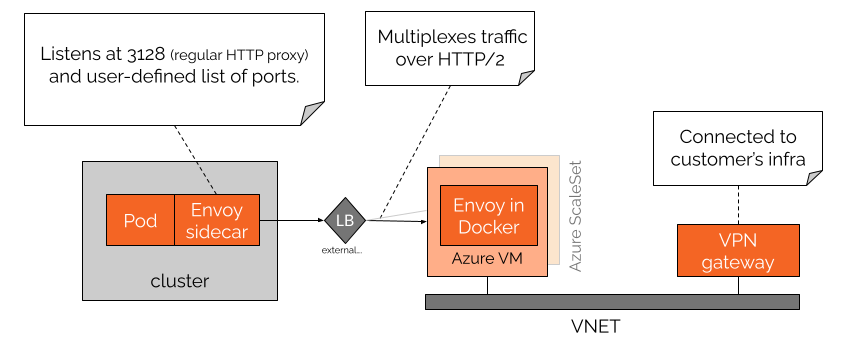
Connecting the dots
Some Pods (installed in a Helm release) include an optional Envoy sidecar (switched on/off with some Helm values) that acts as a general purpose HTTP proxy, although it can also be configured for listening at a list of extra ports for forwarding other non-standard TCP traffic.
Envoy multiplexes all this traffic inside a single HTTP/2 connection that is sent to a remote Azure Scale Set where an Envoy counterpart is listening. The Scale Set is behind an Azure Load Balancer, so it can grow/shrink automatically and connectivity is maintained.
The Scale Set is in the same VNET as an Azure VPN Gateway that acts as a gateway to the customer network: they just have to provide the VPN connection details of their side and we will initiate the connection. With the right infrastructure configuration, all the traffic that goes out of the Envoy in the Scale Set can reach the customer's networks though the VPN gateway.
Infrastructure jobs
And how do we create all this infrastructure? First, with a Kubernetes Operator that watches our own Custom Resources that define the infrastructure, with details like the address spaces, VPN IPSEC parameters or the pre-shared key. And second, with some Infrastructure jobs.
What are these Infrastructure jobs? They are regular Pods where we run Terraform. When the operator detects a new Custom Resource (or a modified one) it generates some Terraform configuration in a Secret and it starts a Pod with our Terraform image. We have packaged all our Terraform code inside a Docker image, were we have also added a driver (a simple command line tool that acts as a wrapper for Terraform, using this library for doing things like “terraform apply” from Golang).
Lessons learnt
There are some lessons I have learnt after creating this architecture.
- Terraform is not intended to be automated. Terraform was designed for being used by humans, and there has been little effort into making it an automatizable (does this word exist?) tool. The Go library we use makes things easier, but even so it is a real pain to deal with all the different scenarios from Go.
- Some Terraform providers fail... a lot. For example, the Azure provider sometimes fails with a “operation cannot be completed, please retry again”. I understand that this is a problem in the Azure API, but this kind of retries should be done at the provider level. But most of the time the error is a false negative and the Azure resource was created successfully, so next time the Terraform job is retried... it fails because the resource already exists!
- Remote state. In order to keep things consistent, Terraform must keep the state in a central place. Ideally this state should be saved in the Kubernetes Custom Resource (in particular, in the Status of the object). However, Terraform does not allow custom state backends, so we must save the state in a different place: in an Azure backend (in a blob).
- Infrastructure drifts. The Custom Resource describes the desired state of our infrastructure. After being “applied”, that state is reconciled and things are as we intended them to be. However, as time passes, many things can change in the real infrastructure, either as a result of manual changes or as an unintended side effects, bugs or for other unknown reasons. We don't really know when we lose the sync between the desired and the real states, so the only solution is to periodically “apply” the desired state for forcing a reconciliation. These reconciliations must be applied periodically and in a completely automatic way, so you must be really sure that your infrastructure can support this amount of churn and behaves as cattle and not as a group of expensive pets. I would also like to take a look at things like Crossplane for a possible replacement of Terraform...
- Credentials management is hard. The job must be started with some credentials. Those credentials must be obtained by the Operator and passed to the Job in environment variables. I never thought this would be so difficult (ie, we must get a Vault token, and that process would take a complete blog post). And the worst part is that some Terraform providers (ie, AWS) just hang instead of failing/aborting when the credentials are not valid or expired.